

熵与信息(一):一个石破惊天的副产品
在这个信息洪流汹涌的时代,熵与信息不仅是科学领域的基石,更是我们理解世界的关键。本期给大家上一道“硬菜”,科学声音王木头老师的重磅专栏——《熵与信息》。预计每周一更,共 6~7 期。
理解「熵」的本质可以帮助我们理解信息的无序状态,而如何准确评估信息的可靠性和相关性,对于做出明智决策至关重要。
我们开始吧~
“熵”,这个词大家应该都听过。热力学第二定律描述的就是一个“熵增”的过程。现在很多人想去说一件事开始变得混乱,就爱用“熵增”去形容。 但是你真的理解熵吗?
但是你真的理解熵吗?
在大多数的科普书里都会说,熵表示的是一个系统的混乱程度。然后举例说明,一个整洁有序的房间是比杂乱的房间有更低的熵,一个封闭系统总是会不可逆的熵增,就像是一个房间如果不收拾,总是会越来越乱。
这么理解不能说错,但是一定会让人产生这样一个疑问,房间整洁有序的标准是什么?我认为把衣服叠起来放最有序,那是不是把衣服挂起来就变得混乱了呢?那如果有另一个人认为把衣服挂起来才是有序的,叠起来放相对挂起来才更混乱。如果是这样的话,那么熵就应该是一个主观的概念了。 都说我们的宇宙一直处于熵增状态,这会不会是以宇宙大爆炸为标准,认定那个时候是最有序的状态,宇宙后来的演化才会是越来越混乱。如果改变一下标准呢?我们把未来的宇宙情况定义为是最有序的情况呢?会不会宇宙大爆炸的时候才是相对更混乱的情况呢?宇宙的发展其实是在熵减?
都说我们的宇宙一直处于熵增状态,这会不会是以宇宙大爆炸为标准,认定那个时候是最有序的状态,宇宙后来的演化才会是越来越混乱。如果改变一下标准呢?我们把未来的宇宙情况定义为是最有序的情况呢?会不会宇宙大爆炸的时候才是相对更混乱的情况呢?宇宙的发展其实是在熵减?
我想绝大多数的人在第一次听到熵这个概念的时候都会有这样疑问。不只是别人,就是我自己也是如此。
会有这样的疑问,最根本的原因还是完全在用举例类比的方式去理解熵本意。但这样是远远不够的,熵的含义要深刻的多。在现在,熵所涉及的领域已经远远超过了热力学本身,通讯、密码学就不用说了,复杂科学、统计学、金融,以及人工智能背后都有熵的影子。尤其是人工智能,熵更是其中的核心概念。所有人工智能从数据中学习规律,本质上就是一个求解最大熵的过程;想训练 AI 模型,就需要当前模型参数和真实数据的差距,而这个差距的标准就是它们之间的交叉熵。

应该如何理解熵呢?
熵这个概念是一定要和信息放在一起理解,才能明白其本质的含义。即便是熵这个词最开始是来自于热力学的,但只是用物理学的视角,也很难抓住熵这个概念的深刻含义。
所以,要想对熵的本质有更进一步的理解,就需要把对什么是熵的描述升升级。把“熵是对系统混乱程度的描述”,变成“熵是对一个系统里信息总量的一种度量方式”。
也就是说理解熵本质的前提是理解信息。
最初熵只是香农研究信息的副产品
我们都知道,信息论的建立者是克劳德·香农。任何一门新学科的开创都是非常困难的,而香农就是凭借着一己之力开辟出了一门前无古人的学科。
而且,信息论在香农手上可以说是开局即巅峰,仅凭 1948 年发表的一篇叫做《通信的数学理论》的论文,不只是开创了信息论,还让信息论的理论体系及其扎实,后人只能扩展无法超越。

现在在大学课堂里学到的关于信息论的知识,像是编码、信道容量、通讯系统优化等 ,其实都是这篇论文里的内容。
香农之所以会做出这么多前人想做没有做到的事,就是因为他作对了一件事,他找到了一种非常合理的方法对信息进行定量描述。
这其实就很像是牛顿。牛顿对力学的贡献可以说是前人的许多倍,但并不是说牛顿就比伽利略、惠更斯要聪明许多倍,而是牛顿比前人多做对了一件事,他将力定义为了 F=ma 然后很多复杂的问题就变得迎刃而解了。这层窗户纸捅破之后,后续的问题都变得豁然考虑。
香农也是,他捅破的窗户纸就是定义了信息量,可以用它统一衡量一个消息里所含信息大小。
定义出信息量,香农就基于这个概念做了很多研究,其中有一个副产品。最开始,香农对于这个副产品是什么也没有什么概念,只是用一个没有具体含义的 H 符号来代替。本意是用一个数学指标去衡量一个系统里所有可能性的信息量。
结果,很快冯·诺伊曼看到了这篇论文,而且还敏锐地就注意到了这个 H。因为只需要把 H 的公式带入到物理系统里,这 H 最后计算出了的就是热力学中的“熵”。
冯·诺伊曼写信把自己的告诉了香农。香农也接受了冯·诺伊曼的建议。于是在后来的论文和著作中,他正式采用了“信息熵”这个术语。于是“熵”这个词给信息论与热力学、乃至整个物理学之间都建立起来一种深层次的联系。而这个联系,也为后来的研究带来了许许多多的灵感。
所以,想要理解熵,尤其是用信息论的角度去理解上,我们就需要先理解香农口中的信息量到底是什么?
信息会降低系统的不确定性
信息量是对一个消息里含有信息多少的定量描述。
其实,对于信息别说定量了,就是定性的去描述都很困难。信息这个概念非常的特别,它不像物理对象一样,是某个可以观察到的实体,实体只能算是信息的载体。
不同的实体完全可以承载同样的信息。这就导致,我们很难说清楚信息的本质是什么东西。一段语音可以是信息,一个图案可以是信息,一段 DNA 可以是信息,一个光子可以是信息,一个符号也可以是信息。它们的共同之处是什么呢?

香农的厉害之处就在于,他把这些不同载体上的信息统一了起来。香农认为信息不论载体是什么,它都是一种可以减少不确定的东西。
比如高考刚考完,你还不知道成绩,这个时候高考分数就是不确定的。你可能考个高分,也可能考个低分。但是一旦你查了高考分,这个不确定就消除了。
还有看世界杯,8 强已经产生了,到底谁会得冠军呢?不知道。但是只要决赛一踢完,你一看新闻,这个不确定性就消失了。
还有当电脑里某个字节没有存储数据的时候,它里面的二进制情况是不确定的。直到接收到了一个存储的信息,这个字节里的二进制情况被确定了下来。
所以,将信息定性地理解为可以降低系统的不确定性就非常合理。但只是这样的话还是无法满足对信息的定量描述,也就是说如何理解一条消息里面那个包含的信息的多少呢?也就是不确定性被消除了多少呢?
消息量是对“惊讶程度”的度量
香农对于信息的定量描述,其实也不是凭空想出来的,而是对我们直觉习惯进行归纳,然后用一个数学方式呈现出来的。所以,如何衡量一个消息所含信息的多少,我们需要先看看我们的直觉习惯是怎样的。
比如,一个月考次次都是考 680 分的同学,如果高考成绩出来了,他考了 700 分,这个消息所含的信息是多还是少呢?如果高考成绩出来,他只考了 300 分,这个消息是比前一种情况信息量更多呢,还是更少呢?
还有,一天醒来,你得到消息说中国的夺得了世界杯冠军,和这个消息相比,阿根廷夺得冠军的消息是包含的信息更多呢还是更少呢?
比较麻烦的是这种情况。计算机存储了一个字节的数据,它接收的数据是 11101000,或者是 11110111,这两个数据的信息量一样吗?
前面两种情况比较容易理解。一个平时学习很好的学生,如果最后知道自己考了一个好成绩,这个消息其实没有什么特别的。而如果是平时一直学习好,最后考了一个特别差的成绩,这个消息才算让人惊讶,或者说这个消息所包含的信息量应该是更多的。
同样的道理,阿根廷和中国相比,阿根廷夺冠虽然也是提供了一定的信息量,但是中国队夺冠了,这个信息才能算是让人震惊。
我们习惯上肯定是觉得一个消息越让人震惊,就越是有料,所包含的信息也就越多。但是这个震惊应该如何用数学描述呢?
不论是知道高考成绩,还是知道世界杯冠军,这两种情况接受信息后都是从多个可能结果中变成了一个确定的结果,也可以说它们的“终点”都是相同的。
不同的其实是“起点”,一个好学生考好成绩的可能性本来就很大,最后结果是它真的考了一个好成绩,这只是从一个大概率事件变成了一个确定事件,跨越过的可能性比较小。相反,他考出一个很差的成绩是一个小概率事件,如果最后的消息真的是他考出来一个很差的成绩,从一个小概率事件变成一个确定事件,跨越过的可能性就比较大。
所以,从我们的习惯中可以看出来,一个消息的信息量的多少,其实就是这个消息的“惊讶程度”,而这个惊讶程度又是和概率的变化情况有关的。一个小概率事件变成了确定事件,惊讶程度就高,信息量就大。
理解信息量为什么如此计算
既然这样的话,那就太方便了。概率越小的事情发生了,那么惊讶度就越大,而概率这个数学概念是现成的,我们直接用概率值作为信息量的定量描述就可以了。
如果考虑问题只考虑前面的情况,这么做完全没有问题,但是事情并没有那么简单,我们还需要考虑这样一种情况——消息是可以分开传递的。
拿前面足球的例子来说,“阿根廷队夺冠了”这一个消息所包含的信息量,是不是和“阿根廷进决赛了”加“阿根廷赢得了决赛”,这两个消息合在一起的信息量是一样的。都是从八强到最后的冠军,起点终点都一样。
这样的话,那是不是我们应该得出一个特别符合直觉的关系,夺冠的信息量=进入决赛的信息量+赢得决赛的信息量。
信息量是可以相加的。
这本来没有什么问题,但是如果用概率直接去定量描述信息量的话,问题就来了。
我们把问题做一些简化,假如 8 强里面的每只球队夺冠的概率都是相同的。也就是说阿根廷在 8 强的时候,夺冠的概率是 1/8。
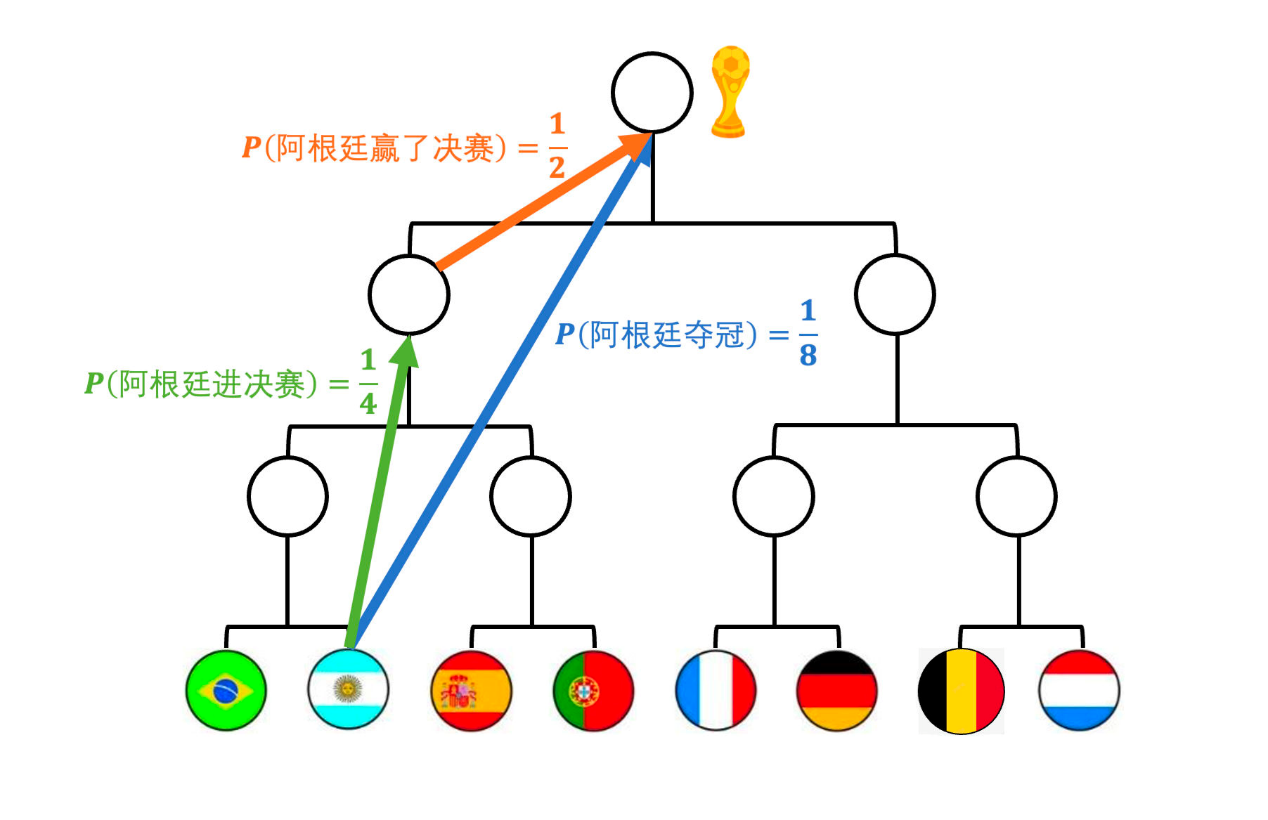
那么阿根廷进入决赛的概率是多少呢?需要赢两场比赛,每场比赛赢球的概率都是 1/2,那么连赢两场的概率就是 1/4。这是进入决赛的概率。
那么赢得决赛的概率呢?就一场比赛了,所以赢球的概率是 1/2。
发现问题了吗?阿根廷夺冠,可以拆分成两个事件,一个是进入决赛,一个是赢得决赛,先要夺冠那么必须这两个事件同时发生。
进入决赛同时赢得比赛,根据概率的基本运算可以知道,两个事件同时发生需要概率想成。1/4* 1/2 正好等于 1/8。
也就是说,我们直觉上感觉信息量应该是一个相加的关系,如果直接套用概率值去表示的话,那么是没有办法满足这一点的。概率值是相乘的关系。
怎么办呢?数学上很简单,就是定一个函数,只需要把概率值传给这个函数,这个函数就可以把相应的信息量返回出来。
这个函数是什么样的?我们现在只对它有一个要求,如果这个函数是 I(P) 的话,这个函数需要满足:
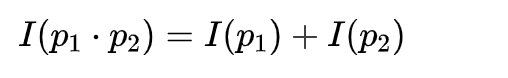
将乘法变成加法,这样的函数你能想到什么?log 对数运算。有没有其他的函数也满足同样的要求呢?不是说绝对不可能,但是从数学上可以证明,初等基本函数里 log 是唯一可以满足要求的情况。所以信息量的计算函数的大框架就已经被定下来了,只不过它的正负号和底应该怎么取还是需要额外进行考虑的。

前面的正负号比较容易确定,概率值越小,越是小概率事件,最后确定后得到的信息量应该越大,所以前面应该是负号,这样得到信息量的数值和概率值的大小正好是相反的。
而对数运算的底,就比较麻烦一点,这里并没有什么绝对的标准,可以是以 10 为底,可以是以 e 为底也可以是以 2 为底。
香农选择的是以 2 为底。这样做的好处是,以 2 为底计算出来的信息量,我们更容易对信息量进行一个直观的想象。它最后计算出来的结果,就相当于是最少可以用几枚理想的硬币可以把这个信息对应事件的概率描述出来。像前面说的,阿根廷在 8 强,夺冠的概率就是 1/8,那么熵与信息(一):一个石破惊天的副产品
在这个信息洪流汹涌的时代,熵与信息不仅是科学领域的基石,更是我们理解世界的关键。本期给大家上一道“硬菜”,科学声音王木头老师的重磅专栏——《熵与信息》。预计每周一更,共 6~7 期。
理解「熵」的本质可以帮助我们理解信息的无序状态,而如何准确评估信息的可靠性和相关性,对于做出明智决策至关重要。
我们开始吧~
“熵”,这个词大家应该都听过。热力学第二定律描述的就是一个“熵增”的过程。现在很多人想去说一件事开始变得混乱,就爱用“熵增”去形容。但是你真的理解熵吗?
在大多数的科普书里都会说,熵表示的是一个系统的混乱程度。然后举例说明,一个整洁有序的房间是比杂乱的房间有更低的熵,一个封闭系统总是会不可逆的熵增,就像是一个房间如果不收拾,总是会越来越乱。
这么理解不能说错,但是一定会让人产生这样一个疑问,房间整洁有序的标准是什么?我认为把衣服叠起来放最有序,那是不是把衣服挂起来就变得混乱了呢?那如果有另一个人认为把衣服挂起来才是有序的,叠起来放相对挂起来才更混乱。如果是这样的话,那么熵就应该是一个主观的概念了。都说我们的宇宙一直处于熵增状态,这会不会是以宇宙大爆炸为标准,认定那个时候是最有序的状态,宇宙后来的演化才会是越来越混乱。如果改变一下标准呢?我们把未来的宇宙情况定义为是最有序的情况呢?会不会宇宙大爆炸的时候才是相对更混乱的情况呢?宇宙的发展其实是在熵减?
我想绝大多数的人在第一次听到熵这个概念的时候都会有这样疑问。不只是别人,就是我自己也是如此。
会有这样的疑问,最根本的原因还是完全在用举例类比的方式去理解熵本意。但这样是远远不够的,熵的含义要深刻的多。在现在,熵所涉及的领域已经远远超过了热力学本身,通讯、密码学就不用说了,复杂科学、统计学、金融,以及人工智能背后都有熵的影子。尤其是人工智能,熵更是其中的核心概念。所有人工智能从数据中学习规律,本质上就是一个求解最大熵的过程;想训练 AI 模型,就需要当前模型参数和真实数据的差距,而这个差距的标准就是它们之间的交叉熵。
应该如何理解熵呢?
熵这个概念是一定要和信息放在一起理解,才能明白其本质的含义。即便是熵这个词最开始是来自于热力学的,但只是用物理学的视角,也很难抓住熵这个概念的深刻含义。
所以,要想对熵的本质有更进一步的理解,就需要把对什么是熵的描述升升级。把“熵是对系统混乱程度的描述”,变成“熵是对一个系统里信息总量的一种度量方式”。
也就是说理解熵本质的前提是理解信息。
最初熵只是香农研究信息的副产品
我们都知道,信息论的建立者是克劳德·香农。任何一门新学科的开创都是非常困难的,而香农就是凭借着一己之力开辟出了一门前无古人的学科。
而且,信息论在香农手上可以说是开局即巅峰,仅凭 1948 年发表的一篇叫做《通信的数学理论》的论文,不只是开创了信息论,还让信息论的理论体系及其扎实,后人只能扩展无法超越。
现在在大学课堂里学到的关于信息论的知识,像是编码、信道容量、通讯系统优化等 ,其实都是这篇论文里的内容。
香农之所以会做出这么多前人想做没有做到的事,就是因为他作对了一件事,他找到了一种非常合理的方法对信息进行定量描述。
这其实就很像是牛顿。牛顿对力学的贡献可以说是前人的许多倍,但并不是说牛顿就比伽利略、惠更斯要聪明许多倍,而是牛顿比前人多做对了一件事,他将力定义为了 F=ma 然后很多复杂的问题就变得迎刃而解了。这层窗户纸捅破之后,后续的问题都变得豁然考虑。
香农也是,他捅破的窗户纸就是定义了信息量,可以用它统一衡量一个消息里所含信息大小。
定义出信息量,香农就基于这个概念做了很多研究,其中有一个副产品。最开始,香农对于这个副产品是什么也没有什么概念,只是用一个没有具体含义的 H 符号来代替。本意是用一个数学指标去衡量一个系统里所有可能性的信息量。
结果,很快冯·诺伊曼看到了这篇论文,而且还敏锐地就注意到了这个 H。因为只需要把 H 的公式带入到物理系统里,这 H 最后计算出了的就是热力学中的“熵”。
冯·诺伊曼写信把自己的告诉了香农。香农也接受了冯·诺伊曼的建议。于是在后来的论文和著作中,他正式采用了“信息熵”这个术语。于是“熵”这个词给信息论与热力学、乃至整个物理学之间都建立起来一种深层次的联系。而这个联系,也为后来的研究带来了许许多多的灵感。
所以,想要理解熵,尤其是用信息论的角度去理解上,我们就需要先理解香农口中的信息量到底是什么?
信息会降低系统的不确定性
信息量是对一个消息里含有信息多少的定量描述。
其实,对于信息别说定量了,就是定性的去描述都很困难。信息这个概念非常的特别,它不像物理对象一样,是某个可以观察到的实体,实体只能算是信息的载体。
不同的实体完全可以承载同样的信息。这就导致,我们很难说清楚信息的本质是什么东西。一段语音可以是信息,一个图案可以是信息,一段 DNA 可以是信息,一个光子可以是信息,一个符号也可以是信息。它们的共同之处是什么呢?
香农的厉害之处就在于,他把这些不同载体上的信息统一了起来。香农认为信息不论载体是什么,它都是一种可以减少不确定的东西。
比如高考刚考完,你还不知道成绩,这个时候高考分数就是不确定的。你可能考个高分,也可能考个低分。但是一旦你查了高考分,这个不确定就消除了。
还有看世界杯,8 强已经产生了,到底谁会得冠军呢?不知道。但是只要决赛一踢完,你一看新闻,这个不确定性就消失了。
还有当电脑里某个字节没有存储数据的时候,它里面的二进制情况是不确定的。直到接收到了一个存储的信息,这个字节里的二进制情况被确定了下来。
所以,将信息定性地理解为可以降低系统的不确定性就非常合理。但只是这样的话还是无法满足对信息的定量描述,也就是说如何理解一条消息里面那个包含的信息的多少呢?也就是不确定性被消除了多少呢?
消息量是对“惊讶程度”的度量
香农对于信息的定量描述,其实也不是凭空想出来的,而是对我们直觉习惯进行归纳,然后用一个数学方式呈现出来的。所以,如何衡量一个消息所含信息的多少,我们需要先看看我们的直觉习惯是怎样的。
比如,一个月考次次都是考 680 分的同学,如果高考成绩出来了,他考了 700 分,这个消息所含的信息是多还是少呢?如果高考成绩出来,他只考了 300 分,这个消息是比前一种情况信息量更多呢,还是更少呢?
还有,一天醒来,你得到消息说中国的夺得了世界杯冠军,和这个消息相比,阿根廷夺得冠军的消息是包含的信息更多呢还是更少呢?
比较麻烦的是这种情况。计算机存储了一个字节的数据,它接收的数据是 11101000,或者是 11110111,这两个数据的信息量一样吗?
前面两种情况比较容易理解。一个平时学习很好的学生,如果最后知道自己考了一个好成绩,这个消息其实没有什么特别的。而如果是平时一直学习好,最后考了一个特别差的成绩,这个消息才算让人惊讶,或者说这个消息所包含的信息量应该是更多的。
同样的道理,阿根廷和中国相比,阿根廷夺冠虽然也是提供了一定的信息量,但是中国队夺冠了,这个信息才能算是让人震惊。
我们习惯上肯定是觉得一个消息越让人震惊,就越是有料,所包含的信息也就越多。但是这个震惊应该如何用数学描述呢?
不论是知道高考成绩,还是知道世界杯冠军,这两种情况接受信息后都是从多个可能结果中变成了一个确定的结果,也可以说它们的“终点”都是相同的。
不同的其实是“起点”,一个好学生考好成绩的可能性本来就很大,最后结果是它真的考了一个好成绩,这只是从一个大概率事件变成了一个确定事件,跨越过的可能性比较小。相反,他考出一个很差的成绩是一个小概率事件,如果最后的消息真的是他考出来一个很差的成绩,从一个小概率事件变成一个确定事件,跨越过的可能性就比较大。
所以,从我们的习惯中可以看出来,一个消息的信息量的多少,其实就是这个消息的“惊讶程度”,而这个惊讶程度又是和概率的变化情况有关的。一个小概率事件变成了确定事件,惊讶程度就高,信息量就大。
理解信息量为什么如此计算
既然这样的话,那就太方便了。概率越小的事情发生了,那么惊讶度就越大,而概率这个数学概念是现成的,我们直接用概率值作为信息量的定量描述就可以了。
如果考虑问题只考虑前面的情况,这么做完全没有问题,但是事情并没有那么简单,我们还需要考虑这样一种情况——消息是可以分开传递的。
拿前面足球的例子来说,“阿根廷队夺冠了”这一个消息所包含的信息量,是不是和“阿根廷进决赛了”加“阿根廷赢得了决赛”,这两个消息合在一起的信息量是一样的。都是从八强到最后的冠军,起点终点都一样。
这样的话,那是不是我们应该得出一个特别符合直觉的关系,夺冠的信息量=进入决赛的信息量+赢得决赛的信息量。
信息量是可以相加的。
这本来没有什么问题,但是如果用概率直接去定量描述信息量的话,问题就来了。
我们把问题做一些简化,假如 8 强里面的每只球队夺冠的概率都是相同的。也就是说阿根廷在 8 强的时候,夺冠的概率是 1/8。
那么阿根廷进入决赛的概率是多少呢?需要赢两场比赛,每场比赛赢球的概率都是 1/2,那么连赢两场的概率就是 1/4。这是进入决赛的概率。
那么赢得决赛的概率呢?就一场比赛了,所以赢球的概率是 1/2。
发现问题了吗?阿根廷夺冠,可以拆分成两个事件,一个是进入决赛,一个是赢得决赛,先要夺冠那么必须这两个事件同时发生。
进入决赛同时赢得比赛,根据概率的基本运算可以知道,两个事件同时发生需要概率想成。1/4* 1/2 正好等于 1/8。
也就是说,我们直觉上感觉信息量应该是一个相加的关系,如果直接套用概率值去表示的话,那么是没有办法满足这一点的。概率值是相乘的关系。
怎么办呢?数学上很简单,就是定一个函数,只需要把概率值传给这个函数,这个函数就可以把相应的信息量返回出来。
这个函数是什么样的?我们现在只对它有一个要求,如果这个函数是 I(P) 的话,这个函数需要满足:
将乘法变成加法,这样的函数你能想到什么?log 对数运算。有没有其他的函数也满足同样的要求呢?不是说绝对不可能,但是从数学上可以证明,初等基本函数里 log 是唯一可以满足要求的情况。所以信息量的计算函数的大框架就已经被定下来了,只不过它的正负号和底应该怎么取还是需要额外进行考虑的。
前面的正负号比较容易确定,概率值越小,越是小概率事件,最后确定后得到的信息量应该越大,所以前面应该是负号,这样得到信息量的数值和概率值的大小正好是相反的。
而对数运算的底,就比较麻烦一点,这里并没有什么绝对的标准,可以是以 10 为底,可以是以 e 为底也可以是以 2 为底。
香农选择的是以 2 为底。这样做的好处是,以 2 为底计算出来的信息量,我们更容易对信息量进行一个直观的想象。它最后计算出来的结果,就相当于是最少可以用几枚理想的硬币可以把这个信息对应事件的概率描述出来。像前面说的,阿根廷在 8 强,夺冠的概率就是 1/8,那么
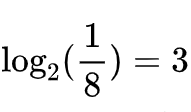
表示可以用 3 枚硬币就完全表示出来。只不过,现实中没办法出现类似 1.2 个硬币的情况,在数学计数却是可以计算出 1.2 的。
硬币还是过于具体了,抽象一下的话,一个硬币就相当是一个二进制数,这样的话信息量的大小也就是可以最少用多少个二进制数就给描述出来。
以 2 为底计算出来的信息量是有单位的,那就是我们熟悉的 bit,而我们现在用 1bit 表示一个二进制数也正是这个原因。
如果是以 e 为底,那么计算出来的信息就不是 bit 了,它的单位是那特(nat),如果是以10为底的话,单位就是哈特利(Hart)或狄特(dit)了。
现在我们得到了和香农一样的结论,信息量是:
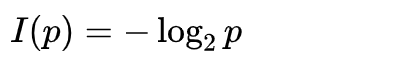
我们前面其实还留下了一个问题没有解决。举例子的时候,我还举例了,一个电脑如果接收到了两个数据分别是11101000和11110111,那么这两个数据的信息量一样吗?
乍一看,这不都是 8bit 的数据吗,都是 8bit,那么应该信息量是一样的对吧。我先公布答案啊,其实这个问题并没有这么简单。
那么具体问题出在哪儿?如果我不说,你可能都没有意识到有问题,而要想了解到其中隐藏的问题,那么就需要从熵的视角去考虑问题了。
熵到底是什么?和信息量是怎样的关系,我们下一期继续聊。
信息量有单位无量纲
最后,关于信息量再额外补充一些内容。这些内容虽然对应后面理解熵并没有什么直接的关系,但的确都是非常有趣的知识点。
首先我问一下大家,信息量的单位是 bit,那么信息量的量纲是什么呢?
现在规定的基础量纲有 7 个,分别是长度,质量,温度,电流,时间,物质的量,发光强度,其他所有的量纲都是由这 7 个量纲组成的。
我们通常认为量纲是和单位有关的,每个基础量纲对应的国际标准单位也都是最基础的单位。没有量纲的情况的确有,像是 π,比值,都是无量纲的量,但是它们也没有单位啊。
而信息量有单位,但是它没有量纲。这其实也可以很好的体现出信息本质上是脱离物理世界的。虽然没有物理世界里的东西作为载体也不会有信息,但是信息具体是什么,信息量的大小,是不依赖物理世界的。比起物理量,信息量更像是一个纯粹数学领域里的量。
信息量可以等价切换为分贝
还有一点,想多介绍一下信息量公式里的那个负号。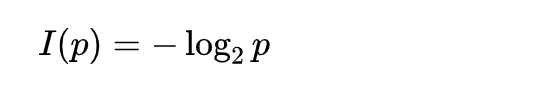
前面为了把问题简化,我说了前面加负号,是因为和概率值的大小相反,这样讲的确没有问题,不过不全面。只需要对公式变一下形,对数 log 运算,前面的符号是可以拿进 log 里面的。拿进里面之后,里面会变成倒数。也就是信息量公式:
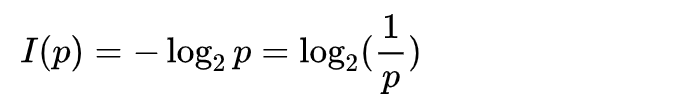
这有什么特别的呢?我把经常用来表示音量大小的分贝的计算公式写出来,大家对比一下应该就能看出来了。
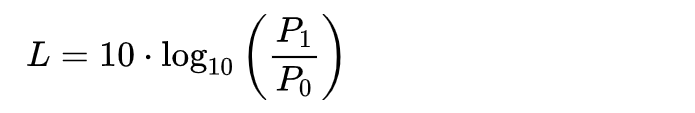
其中 L 是分贝数,P1 是要测量的物理量(如功率、电压等等),P0 是参考值或基准值,通常是一个选定的标准值。
分贝的计算公式是不是和信息量的计算公式非常的像,除了系数和底数就是一样的。
只不过,信息量公式 log 里面的分母是一个概率值,分子 1 如果也可以看作是概率。按照分贝公式的意义,信息量就是以事情发生的概率(分母的 p)作为基准,然后用最后确定的概率值 1 去做比较,看看最后的数值是多少。
也就是说,不同可能性的事件,在计算信息量的时候选择的它们的概率值 p 会不一样,那么 p 作为基础刻度也就不一样了,只不过这个时候测量的那个对象都是相同的,都是确定发生的概率,也就是分子的 1。然后看看 1 和 p 中间差了多少倍,然后这个倍数再进行 log 运算。
所以,如果想的话信息量是可以换成分贝的,声音的分贝是声音的相对强度,无线电信号的分贝是信号的相对强度,信息量的分贝其实衡量的就是一个消息带来的惊讶程度。
好了,我们下次去看什么是熵。
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国