

顺序统计量估计是指用顺序统计量或其函数构造的估计。如,用极差估计标准差;用最小和最大观测值估计均匀分布区间的两个端点等1。
基本介绍顺序统计量设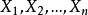 是总体X的样本,将它们自小到大排成
是总体X的样本,将它们自小到大排成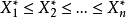 ,则这个排列称为样****本顺序统计量。抽取一个样本
,则这个排列称为样****本顺序统计量。抽取一个样本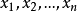 ,便有一组自小到大的观察值
,便有一组自小到大的观察值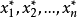 与之相对应,其中
与之相对应,其中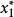 是观察值中最小者,
是观察值中最小者, 是观察值中最大者。例如,样本值为3.15,2.98,3.16,3.05,2.90,则其顺序统计量为2.90,2.98,3.05,3.15,3.162。
是观察值中最大者。例如,样本值为3.15,2.98,3.16,3.05,2.90,则其顺序统计量为2.90,2.98,3.05,3.15,3.162。
顺序统计量估计法 顺序统计量估计法是直观简便的估计法,常常是对总体的数学期望与标准差进行。
设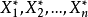 为总体X的样本顺序统计量,则称
为总体X的样本顺序统计量,则称
 为样本中位数。
为样本中位数。
样本中位数 的观察值
的观察值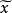 的取值规则是:将样本观察值自小到大排成顺序统计量观察值,当n为奇数(即n=2k+1)时,取居中的数据
的取值规则是:将样本观察值自小到大排成顺序统计量观察值,当n为奇数(即n=2k+1)时,取居中的数据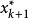 ;当n为偶数(n=2k)时,取居中两个数据的平均值
;当n为偶数(n=2k)时,取居中两个数据的平均值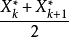 ,即
,即
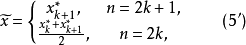
从中位数的含义可见,它带来了总体X取值的平均数信息,因此,用于估计总体X的数学期望是合适的。用样本中位数估计总体X的数学期望的方法,称数学期望E(X)的顺序统计量估计法。其结果也有估计量与估计值之分2。
例题解析为了估计某批灯泡的平均寿命 [即寿命X的数学期望E(X)],随机抽取7个灯泡测得寿命数据为(单位:h):1 575,1 503,1 346,1 630,1 575,1 453,1 650。
[即寿命X的数学期望E(X)],随机抽取7个灯泡测得寿命数据为(单位:h):1 575,1 503,1 346,1 630,1 575,1 453,1 650。
试用顺序统计量估计法估计 。
。
解: 因为样本顺序统计量观察值为:1 346,1 453,1503,1575,1 575,1 630,1 650,n=7为奇数,所以由式(5)得的顺序统计量估计值为
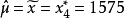 若用矩估计法,则得
若用矩估计法,则得
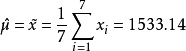
两种估计法所得结果稍有差异。
用样本中位数估计总体X的数学期望的优点是:
(1)计算简便。这一优点可直接从中位数的取值规定看出。
(2)所得估计值不易受个别异常数据影响。例如,在寿命试验的样本值中,发现某一个数据异常小(比如说,在上例所得样本观察值中,由于工作人员粗心,将1346误记成134),在作统计推断时,一定会提出疑问:这个异常小的数据是总体X的随机性造成的,还是受外来干扰造成的呢?当原因属于后者(如记录错误),那么用样本平均值估计E(X)时显然受到影响(使估计值偏低)。但用样本中位数估计E(X)时,由于一个(甚至几个)异常小(或异常大)的数据不易改变中位数的取值,这种特点常说成具有稳健性。读者一定见过:当有n位评委对某人艺术表演评分,裁判计算表演者得分时,总是先去掉一个最高分,去掉一个最低分,然后取n-2个保留分的平均值,这实际上是综合运用顺序统计量法与矩估计法的结果,如果评委只有三位或四位,则上述评分方法就是顺序统计量法,也称中位数法。
(3)简化试验过程。在寿命试验中,个别样品寿命很长,这是常有的现象(如上例)中,若有一个灯泡寿命为1 950 h,比平均寿命1 575 h长很多)。等待n个寿命试验全部结束,然后对平均寿命作估计,时间花得太多。如果确定用顺序统计量法估计总体的数学期望,那么,将n个试验同时进行,只要有超过半数的试验得到了寿命数据,无论其余试验结果如何,都可得到样本中位数的取值。例如,在上例中,7个寿命试验同时进行,只要完成4个试验,并得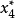 =1 575(h),便得到了总体平均寿命的顺序统计量估计值为
=1 575(h),便得到了总体平均寿命的顺序统计量估计值为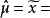 1 575(h)。如果没有其它需要,寿命试验即可结束。
1 575(h)。如果没有其它需要,寿命试验即可结束。
顺序统计量也可用于对总体X的标准差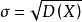 作估计2。
作估计2。
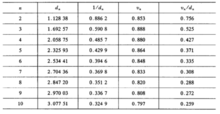
用顺序统计量估计参数样本中位数和样本极差都是顺序统计量的函数,这类函数计算简便,且不受样本中异常值的影响.无论x服从何种分布,都可以样本中位数殳作为总体均值E(x)的估计量,以样本极差作为总体标准差的估计量,不过这种
估计一般来说比较粗糙,对于正态总体,样本中位数的渐近分布由下面的定理给出。3
本词条内容贡献者为:
尹维龙 - 副教授 - 哈尔滨工业大学
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国